【通往数据自由之路导读】好久不见,手提代码来见,这篇文章分享的是一点资讯新闻网站的抓取和数据分析,机器学习。直接放代码!
流程思路:一点资讯是一个类似今日头条的新闻资讯类网站,我们通过抓取一点资讯上不同类别的新闻(一共5种类型的新闻,1403篇文章,190+万字),得到原始的数据素材。然后对其进行数据分析,生成词云,同时运用机器学习方法对其进行预测分类,并统计正向和反向情感。
首先:进行数据的抓取,主要函数如下:
#抓取新闻数据,主代码太长,这里贴了图片。
这里主要通过下面类型格式的url去抓取链接,然后通过得到的新闻详情页面url进行内页的抓取。
http://www.yidianzixun.com/home/q/news_list_for_channelchannel_id=c9&cstart=20&cend=40&infinite=false&refresh=1
由于一点资讯也是整个不同新闻网站的信息的综合性网站,所以新闻内页会有编码格式和布局格式的不同。在这里需要特别注意一下。
下一步:进行数据分析和文本
中文文本处理的过程中特别需要注意绘图时中文乱码的问题。
# 绘图之前的一些操作步骤# 防止中文字乱码
from pylab import mpl
mpl.rcParams[font.sans-serif] = [Microsoft YaHei] # 指定默认字体
# 解决保存图像是负号-显示为方块的问题
# 字体大小
mpl.rcParams[axes.unicode_minus] = False font_size = 10
# 图表大小
fig_size = (12, 9)
# 更新字体大小mpl.rcParams[font.size] = font_size
# 更新图表大小mpl.rcParams[figure.figsize] = fig_size
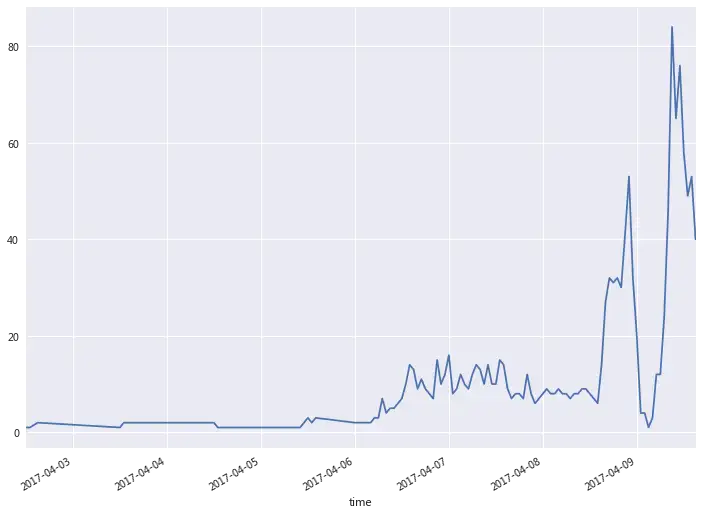
看看新闻发布的时间段。
#按照日期的字符串进行排序
df_time = df.sort_values(date, ascending=[0])
# 删除原来的索引,重新建立索引
df_time = df_time.reset_index(drop = True)
# 采用计算每个时间段发布次数进行聚合
df_time1 = copy.deepcopy(df_time)
df_time1[time] = [time.strftime(“%Y-%m-%d %H”,time.strptime(str(postTime), %Y-%m-%d %H:%M:%S)) for postTime in df_time1[date]]
time_count = (df_time1.loc[:, [time, title]]).groupby([time]).count()
time_count.index = pd.to_datetime(time_count.index)
# 查看每个时间段发布次数,作图
time_count[title].plot()
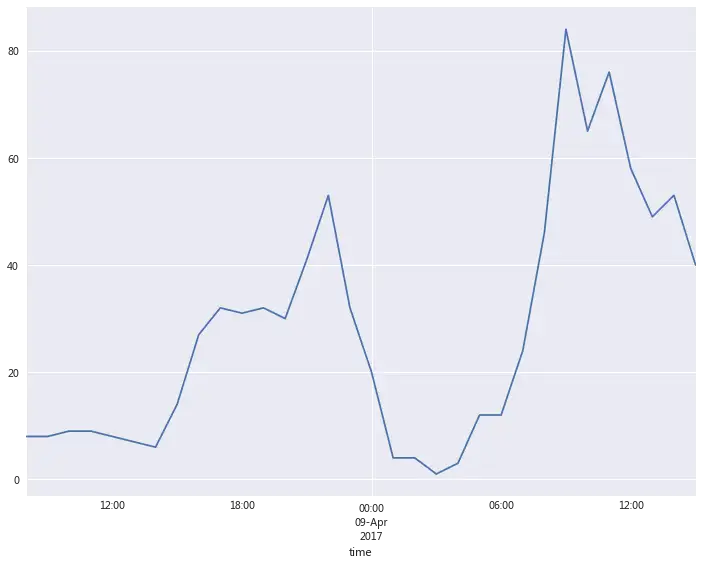
# 缩短时间再进行观察
time_count[title][70:].plot()
新闻发布的时间也是跟我们正常人的作息时间是差不多的,早上9点打到一个高潮,晚上21-22点达到一个高潮。
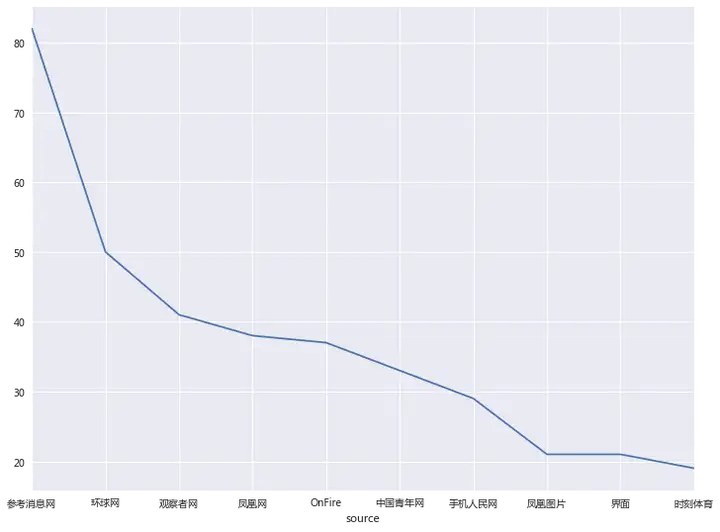
再来看看抓取的这几个类别中,哪个新闻数据源的信息量最多。
# 通过source聚类发现哪个信息源被引用的次数较多
source_count = (df_time.loc[:, [source, title]]).groupby([source]).count()
source_count_sort = source_count.sort_values([title], ascending=[0])
# 观察哪些信息源被引用的较多
print(source_count_sort[title][:10])
# 查看每个时间段发布次数,作图
source_count_sort[title][:10].plot()
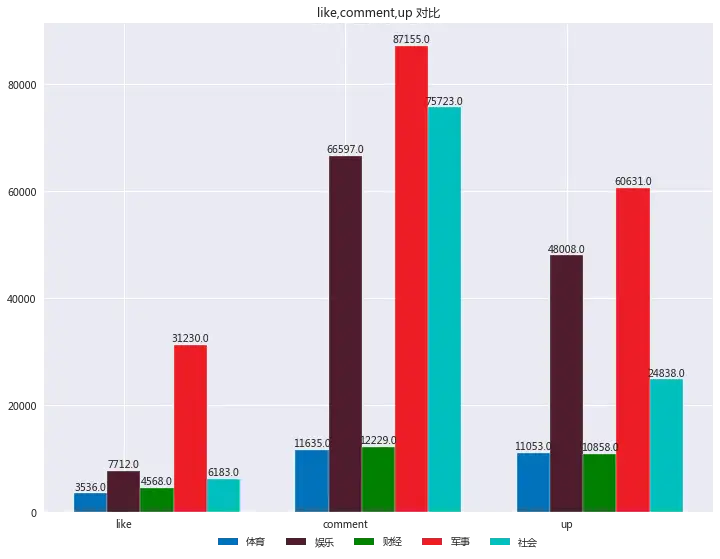
再来看看每个类别的喜欢数、评论数、up数。
(ps:添加数据标签的这个小技巧也是我做了这个项目之后才学会的方法,大家可以借鉴我的这段代码。)
# 构建作图格式
tuple_c = []
for j in range(len(channel_id)):
tuple_c.append(tuple([like[like].iloc[j], comment_count[comment_count].iloc[j], up[up].iloc[j]]))
# 设置柱形图宽度
bar_width = 0.15
index = np.arange(3)
#c2为体育,c3为娱乐,c5为财经,c7为军事,c9为社会,
channel_name = [体育, 娱乐, 财经, 军事, 社会]
# 绘制c2
rects1 = plt.bar(index, tuple_c[0], bar_width, color=#0072BC, label=channel_name[0])
# 绘制c3
rects2 = plt.bar(index + bar_width, tuple_c[1], bar_width, color=#4E1C2D, label=channel_name[1])
# 绘制c5
rects3 = plt.bar(index + bar_width*2, tuple_c[2], bar_width, color=g, label=channel_name[2])
# 绘制c7
rects4 = plt.bar(index + bar_width*3, tuple_c[3], bar_width, color=#ED1C24, label=channel_name[3])
# 绘制c9
rects5 = plt.bar(index + bar_width*4, tuple_c[4], bar_width, color=c, label=channel_name[4])
# X轴标题
plt.xticks(index + bar_width, count_name)
# Y轴范围
#plt.ylim(ymax=100, ymin=0)
# 图表标题
plt.title(ulike,comment,up 对比)
# 图例显示在图表下方
plt.legend(loc=upper center, bbox_to_anchor=(0.5, -0.03), fancybox=True, ncol=5)
# 添加数据标签
def add_labels(rects):
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height, height, ha=center, va=bottom)
# 柱形图边缘用白色填充,纯粹为了美观
rect.set_edgecolor(white)
add_labels(rects1)
add_labels(rects2)
add_labels(rects3)
add_labels(rects4)
add_labels(rects5)
查看评论最多的一篇comment的文章名
# 查看评论最多的一篇comment的文章名
df_comment = df.sort_values(comment_count, ascending=[0])
# 删除原来的索引,重新建立索引
df_comment = df_comment.reset_index(drop = True)
print(df_comment.iloc[0])
title 《人民的名义》40戏骨总片酬4800万 不敌一小鲜肉
source 沈阳晚报
ategory 娱乐
date 2017-04-08 07:38:47
like 159
comment_count 16252
up 5349
detail_fulltext 湖南卫视《人民的名义》播出劲头越来越足,这部集结陆毅、张丰毅、吴刚、许亚军、张凯丽、张志坚、…
确实可以感觉到最近热播的《人民的名义》的火热程度。不过不排除有水军存在。
jieba及词云部分
# 词频统计
contentAll =””
for item in df[detail_fulltext]:
contentAll = contentAll + item
# 查看一共有多少字
print(此次分析的数据中一共有 %d 个字。 %len(contentAll))
此次分析的数据中一共有 1937622 个字。
#分词
segment = []
segs = jieba.cut(contentAll)
for seg in segs:
if len(seg) > 1 and seg!=\r\n:
segment.append(seg)
#去停用词
words_df=pd.DataFrame({segment:segment})
words_df.head()
ancient_chinese_stopwords=pd.Series([我们,没有,可以,什么,还是,一个,就是,这个,怎么,但是,不是,之后,通过,所以,现在,如果,为什么,这些,需要,这样,目前,大多,时候,或者,这样,如果,所以,因为,这些,他们,那么,开始,其中,这么,成为,还有,已经,可能,对于,之后,10,20,很多,其实,自己,当时,非常,表示,不过,出现,认为,利亚,罗斯,” “])
words_df=words_df[~words_df.segment.isin(ancient_chinese_stopwords)]
#统计词频 ,并作图展示
words_stat=words_df.groupby(by=[segment])[segment].agg({“number”:np.size})
words_stat=words_stat.reset_index().sort(columns=”number”,ascending=False)
words_stat_sort = words_stat.sort_values([number], ascending=[0])
sns.set_color_codes(“muted”)
sns.barplot(x=segment, y=number, data=words_stat_sort[:11], color=”b”)
plt.ylabel(出现次数)
plt.title(“前10个最常见词统计”)
plt.show()
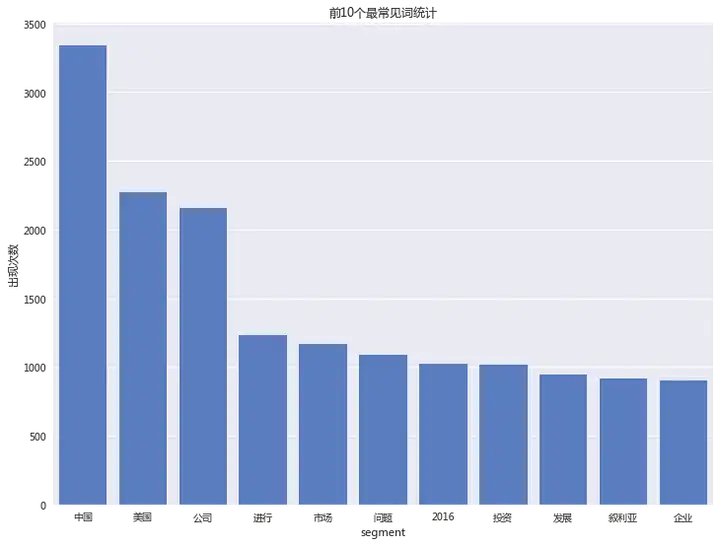
中国,美国,公司,市场等排名靠前。
#进行词云分析
from scipy.misc import imread
import matplotlib.pyplot as plt
from wordcloud import WordCloud,ImageColorGenerator
wordlist_after_jieba = jieba.cut(contentAll, cut_all = True)
wl_space_split = ” “.join(wordlist_after_jieba)
bimg=imread(hhldata.jpg)
my_wordcloud = WordCloud(
background_color=white, # 设置背景颜色
mask = bimg, # 设置背景图片
max_words = 200, # 设置最大现实的字数
stopwords = ancient_chinese_stopwords, # 设置停用词
font_path = msyh.ttf,# 设置字体格式,如不设置显示不了中文
max_font_size = 120, # 设置字体最大值
random_state = 30, # 设置有多少种随机生成状态,即有多少种配色方案
scale=1.5
).generate(wl_space_split)
# 根据图片生成词云颜色
image_colors = ImageColorGenerator(bimg)
#my_wordcloud.recolor(color_func=image_colors)
# 以下代码显示图片
plt.figure(figsize=(12,9))
plt.imshow(my_wordcloud)
plt.axis(“off”)
plt.show()
朴素贝叶斯文本主题分类
# 导入包
import re
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
#构建函数
class LanguageDetector():
def __init__(self, classifier=LogisticRegression(penalty=l2)):
self.classifier = classifier
self.vectorizer = CountVectorizer(ngram_range=(1,2), max_features=20000, preprocessor=self._remove_noise)
def _remove_noise(self, document):
noise_pattern = re.compile(“|”.join([“http\S+”, “\@\w+”, “\#\w+”]))
clean_text = re.sub(noise_pattern, “”, document)
return clean_text
def features(self, X):
return self.vectorizer.transform(X)
def fit(self, X, y):
self.vectorizer.fit(X)
self.classifier.fit(self.features(X), y)
def predict(self, x):
return self.classifier.predict(self.features([x]))
def score(self, X, y):
return self.classifier.score(self.features(X), y)
x = df_2[detail_fulltext]
y = df_2[setType]
# 区分训练集与测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1)
language_detector = LanguageDetector()
language_detector.fit(x_train, y_train)
print(language_detector.score(x_test, y_test))
最后得到的结果为:66.10%(数据量再大一些应该会更高一些)
情感分析
# 求分数
def sentiment_score(senti_score_list):
score = []
for review in senti_score_list:
score_array = np.array(review)
Pos = np.sum(score_array[:, 0])
Neg = np.sum(score_array[:, 1])
AvgPos = np.mean(score_array[:, 0])
AvgPos = float(%.1f%AvgPos)
AvgNeg = np.mean(score_array[:, 1])
AvgNeg = float(%.1f%AvgNeg)
StdPos = np.std(score_array[:, 0])
StdPos = float(%.1f%StdPos)
StdNeg = np.std(score_array[:, 1])
StdNeg = float(%.1f%StdNeg)
score.append([Pos, Neg, AvgPos, AvgNeg, StdPos, StdNeg])
return score
contentAll = contentAll.replace( ,).replace(,,)
#求Pos, Neg, AvgPos, AvgNeg, StdPos, StdNeg的值
start_all_time = time.time()
print(sentiment_score(sentiment_score_list(contentAll)))
end_all_time = time.time()
work_all_time = end_all_time – start_all_time
print(“试验总共所花时间为:%.2f s” % work_all_time)
最后得到的正向词和负向词的得分为:
[[42381391386.625, 32927423863.25, 40668.5, 31596.6, 21539.1, 17724.4]]
总体来看,新闻还是偏正面的。
想要完整jupyter Notebook的同学可以在【通往数据自由之路】公众号中回复:一点资讯
自我介绍何红亮,一位走在数据科学道路上的同学。通过“通往数据自由之路”,希望能记录自己从数据菜鸟到数据能手的进阶之路,分享自己所见、所做、所感。联系邮箱:hhlisme@163.com。
可关注同名知乎专栏和微信公众号:通往数据自由之路。